Digital-Thinking
A blog about applied machine learning, focusing on deep neural networks
 Medium Articles
Medium Articles
- The end of the human-centric web April 5, 2024
- Modern Data Stack: The path to a scalable hybrid cloud solution — part 2 March 18, 2024
- Hidden valuable LLM use cases for eCommerce February 26, 2024
- Modern Data Stack: The path to a scalable hybrid cloud solution — part 1 February 5, 2024
- Building a Visual Search for eCommerce: A Comprehensive Guide November 4, 2023
Blog

How to use additional information from labels to train a plausibility mode Working with predictive deep learning models in practice often comes with the question how far we can trust the predictions of that model. While there are several frameworks…

While the most articles about deep learning are focusing at the modeling part, there are also few about how to deploy such models to production. Some of them (especially on towardsdatascience) say “production”, but they often simply use the unoptimized…
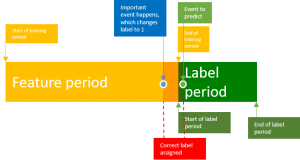
Data leakage in practice is a widely underestimated effect in machine learning, which happens especially where a lot of feature engineering is involved. Data leakage happened even in Kaggle competitions, where winners exploited these systematic flaws in the data. This…
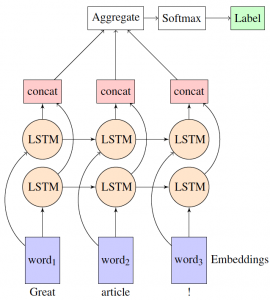
When working with pretrained deep learning models in TensorFlow the input tensor is often fixed and changing a tensor from the beginning of the graph is by design painful. In this post I want to show how to replace tensors…
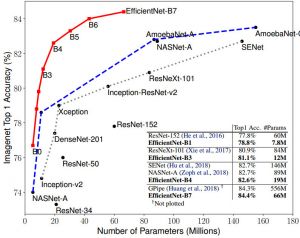
In this post I would like to show how to use a pre-trained state-of-the-art model for image classification for your custom data. For this we utilize transfer learning and the recent efficientnet model from Google. An example for the standford…
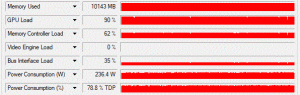
If you ever trained a CNN with keras on your GPU with a lot of images, you might have noticed that the performance is not as good as in tensorflow on comparable tasks. In this post I will show an…
Recently, I wrote a post about the tools to use to deploy deep learning models into production depending on the workload. In this post I will show in detail how to deploy a CNN (EfficientNet) into production with tensorflow serve,…

This is a list of resources for ml/ai engineers and data scientists
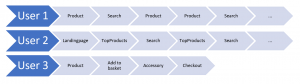
Understanding customer intent by clicks can improve customer journeys and enhance the overall user experience in eCommerce. An understanding of individual customers allows to customize the online experience in several ways. For example, it is possible to show them additional…
After weeks of training and optimizing a neural net at some point it might be ready for production. Most deep learning projects never reach this point and for the rest it’s time to think about frameworks and technology stack. In…
Blogging Fusion Blog Directory