How to use additional information from labels to train a plausibility mode
Working with predictive deep learning models in practice often comes with the question how far we can trust the predictions of that model. While there are several frameworks to verify that it does learn the correct features (e.g. lime, LRP), for unseen data there is still no guaranty that the predicted category is correct. One option to increase the trust into such a model is to introduce plausibility checks. One way to establish such a check, is to use information from the hierarchical structure of the labels, often seen in public datasets (CIFAR-10, Image-Net). The goal is to build a second model, trained on the parent labels in the hierarchy and this post will show why this increases the reliability of models and at what cost.
A flat label structure
Most research for new model architectures and in general better models is based on flat labels, discarding the hierarchy from the datasets. For ImageNet usually 1000 labels are used, Birdsnap uses 500 breeds of birds as labels. There are some models exploiting the hierarchy of these categories like HD-CNNs and Tree-CNNs, but it’s a rather small field.
In practice we often have applications, where our training data is limited and growing over time. The number of images we have per class for training is varying and the accuracy for some labels are worse than for others. From time-to-time new labels occur and we should at least know, how much we can rely on our predictions. In other words, how much can we trust our models?
Probability scores are not reliable on unseen data
The good thing is, that we have probability scores, which we can use to estimate the certainty of predictions. However, when a model faces new data it sometimes gives us high probability scores, even if the prediction is completely off. Particularly in image CNNs with many labels, we can observe unstable predictions, when new data is processed. This problem gets even harder to solve when we are talking about fine grained image classification, where small details in images can make a difference.
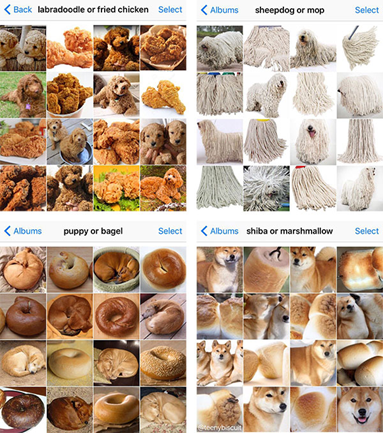
These examples are generally hard to solve, but they show the problem very well. A CNN trained on animal breeds as label is not able to detect food or a mop. CNN’s usually take every shortcut they can to solve the problem and it is obvious that these images appear remarkably similar from the overall colors, shape pose of the objects. As neural networks trained on animals do not understand the concept of a dog, it gets confused and delivers predictions with high confidence for these examples.
But what if we would additionally have a different CNN trained on detecting nose, eyes, and other features, which are representative for animals?
Exploiting the domain knowledge from labels
That’s the idea of plausibility checks. If the second model is trained to detect a different feature, which relates to our label, we can check plausibility. We want to exploit information from the structure of our data.
Another example would be to use the activity information from ImageNet in a second model and check if the activity makes sense in combination with the detected object (of course this information must be encoded in the hierarchy).
With that information it is possible to make use of the implicit domain knowledge in the label structure. One assumption is that a plausibility model benefits from the larger amount of training data per class and generalizes more, therefore overfitting is prevented.
Training a model to check plausibility
The original model is trained on our target labels as they are on the highest granularity (leafs in the label hierarchy). The plausibility model is trained on a higher-level label (parent nodes or related nodes in the graph). To use the animal classifier example the original model is trained on the breed of animals and has 1000 different labels, while the plausibility model is trained to classify the 50 different animals in the data.
A side note:
You might think that it would be much easier to model the hierarchy directly with multiple models e.g one for the animal and after detecting the animal using another one to detect the breed for each animal. And yes that’s possible, but aside from toy data, we usually have a much larger number of classes and nodes in a tree, ending up with hundreds of models ensembled together. This is often not practical.
Another benefit of having a plausibility model is that we can also use images with incomplete label information. We know the animal, but not the exact breed. This happens quite often, when using user feedback for an existing image classification system. A user might not be able to determine the breed of an animal, but knows clearly that it’s a dog. For a a model detecting the breed, these examples are not usable. But for the second model we can include them.
Testing plausibility
When we have trained these two models, we can predict two probability scores one for the fine-grained target label and one for the coarse-grained plausibility label. Due to the reduced number of classes and the higher number of images per class our plausibility model has usually much better accuracy than the original one.
Finally, we get two predictions for an image and need to apply some logic on the results:
- When both scores are high and the original model(e.g. breed) predicts a label, that matches the plausibility prediction(e.g. animal), we can assume that the prediction is correct. Example: 0.98 Dog / 0.89 Akita
- When both scores are low, we know that the result is not reliable or there is simple something else on the image. Example: 0.05 Dog / 0.07 Beagle
- When the original model prediction is low but the second model predicts a high score, we might found a missing label in our training data for the original model (e.g. a missing breed). Example: 0.98 Cat / 0.28 Persian
- When the original model prediction is high and the plausibility model predicts a low score, it might be possible that we have the case shown in the images above. It’s not a cat, but the image is very similar. Example: 0.21 Cat / 0.98 Persian
- And finally, the most interesting case: Let’s say we have a very high probability for our plausibility model, and a medium probability for our original model, but the labels are not plausible: Example: 0.98 Dog / 0.47 Persian. Obviously, a persian is not a dog. But what if we look at the second best prediction in the original model and find a 0.46 for Briard, which actually is a dog? Here it’s plausible to assume that briad is correct. So in general we can apply a logic (or another model), which searches the top-n predictions of the breed model matching a given animal with a minimum score.
Conclusion
Using a plausibility model, where hierarchy information is available in the data, can make predictions more reliable. If the system delivers conflicting scores, we can assume that the prediction is wrong. Furthermore, we can get more insights into possible errors of the model, find missing labels or even correct the prediction by not only looking at the top prediction, but also at the Top-N predictions. On the downside, we need an additional model and introduce logical checks into the system.