After weeks of training and optimizing a neural net at some point it might be ready for production. Most deep learning projects never reach this point and for the rest it’s time to think about frameworks and technology stack. In…
After weeks of training and optimizing a neural net at some point it might be ready for production. Most deep learning projects never reach this point and for the rest it’s time to think about frameworks and technology stack. In…
This is the last post in the series about machine learning in practice. This time the post will be about productionizing machine learning models. I want to share my experience from several production machine learning systems and show how it…
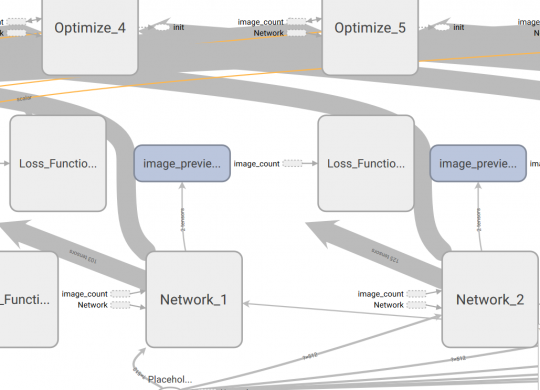
Preprocessing and data transformation are the most important parts of all machine learning pipelines. No matter what type of model you use, if the preprocessing pipeline is buggy, your model will deliver wrong predictions . This remains also true, if…

In this How-To series, I want to share my experience with machine learning models in productions environments. This starts with the general differences to typical software projects and how to acquire and deal with data sets in such projects, goes…
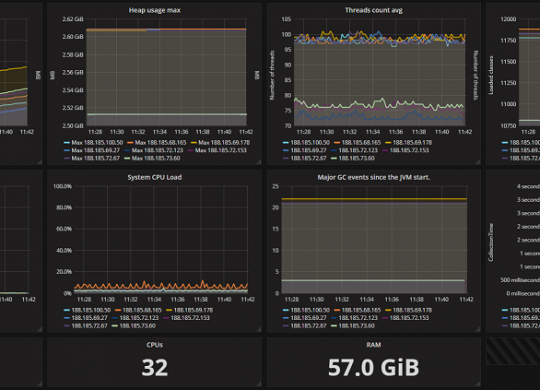
In this post I will show, how to report jmx metrics to logstash via TCP on a push based way, without changing java code from an existing application.

When running Spark 1.6 on yarn clusters, i ran into problems, when yarn preempted spark containers and then the spark job failed. This happens only sometimes, when yarn used a fair scheduler and other queues with a higher priority submitted…

After getting good results with the Random Forest algorithm in the last post, we will take a look at feed forward networks, which are artificial neural networks. Artificial neural networks consist of many artificial neurons, which are based on the…
In the previous post i showed how to use the Support Vector Machine in Spark and apply the PCA to the features. In this post i wills show how to use Decisions Trees on the titanic data and why its better…
In my previous post i showed how to increase the parallelism of spark processing by increasing the number of executors on the cluster. In this post i will try to show how to distribute the data in a way, that the cluster…
This ist the third part of the Kaggle´s Machine Learning by Disaster challenge where i show, how you can use Apache Spark for model based prediction (supervised learning). This post is about support vector machines. The Support Vector Machine (SVM) is…