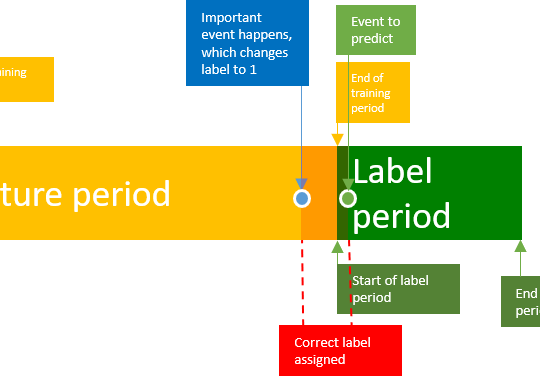
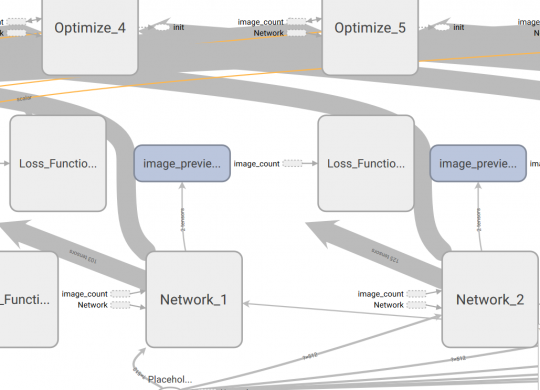
How to use additional information from labels to train a plausibility mode Working with predictive deep learning models in practice often comes with the question how far we can trust the predictions of that model. While there are several frameworks…
March 11, 2021 Read more