In my previous post I showed how to use progressive generative adversarial networks (pGANs) for image synthesis. In this post I show how to use styleGANs on larger images to create customizable images of watches. Additionally, I show how to apply styleGAN on custom data.

The StyleGAN paper has been released just a few months ago (1.Jan 2019) and shows some major improvements to previous generative adversarial networks. Instead of just repeating, what others already explained in a detailed and easy-to-understand way, I refer to this article.
In short, the styleGAN architecture allows to control the style of generated examples inside image synthesis network. That means that it is possible to adjust high level styles (w) of an image, by applying different vectors from W space. Furthermore, it is possible to transfer a style from one generated image to another. These styles are mapped to the generator LOD (level of detail) sub-networks, which means the effect of these styles are varying from coarse to fine.
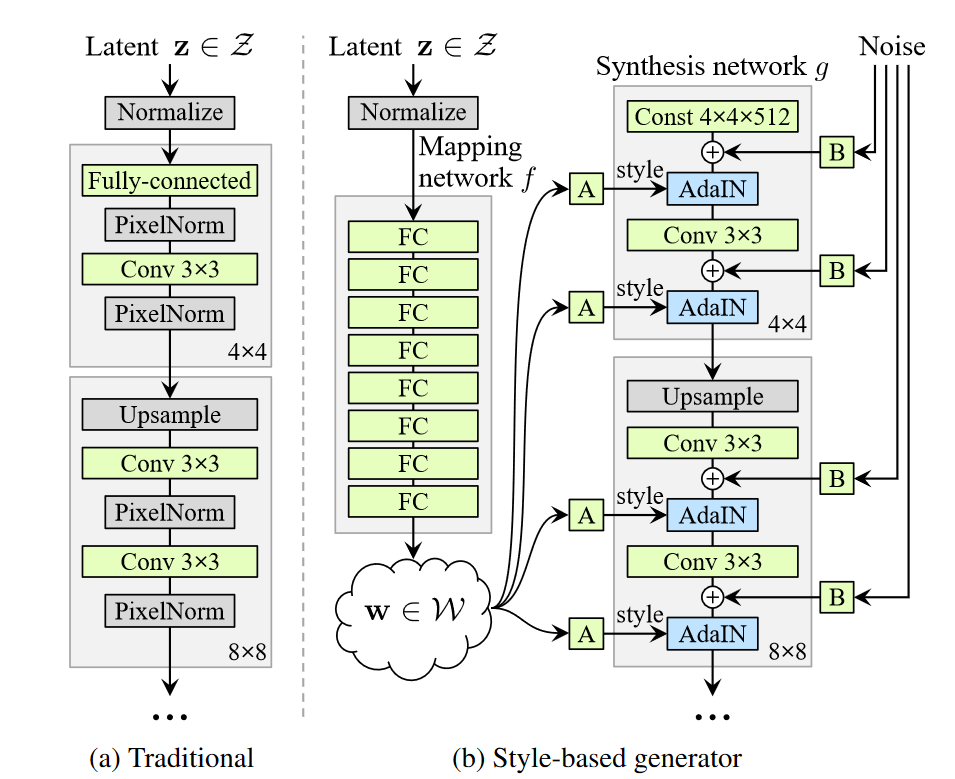
The styleGAN paper used the Flickr-Faces-HQ dataset and produces artificial human faces, where the style can be interpreted as pose, shape and colorization of the image. The results of the paper had some media attention through the website: www.thispersondoesnotexist.com.
StyleGAN on watches
I used the styleGAN architecture on 110.810 images of watches (1024×1024 ) from chrono24. The network has seen 15 million images in almost one month of training with a RTX 2080 Ti. Results are much more detailed then in my previous post (besides the increased resolution) and the learned styles are comparable to the paper results. These images are not curated, so its simply what the GAN produces.




Style mixing
Now lets take a look at the style transfer from one generated image to another:
Pose mixing

Watch mixing

Color mixing

Run styleGAN on your own image data set
- First of all clone the git repository to your local machine
- Make sure to install all the requirements mentioned in the readme.md file (at least 8GB GPU memory required)
- Put all your images into a directory e.g. “E:/image_data” (alternatively you have to change some lines of code in the dataset_tool.py)
- navigate to the repository and run “python create_from_images datasets/mydata_tfrecord E:/image_data”. Mydata_tfrecord it the target folder, make sure to have enough disk space (in my case 50x the size of the source images)
- configure your generated dataset in train.py by adding:
desc += '-custom';
dataset = EasyDict(tfrecord_dir='mydata_tfrecord');
train.mirror_augment = False;
- comment or un-comment the configs, the most of them are self-explaining: important ones: number of GPUs, minibatch_dict (batch_size for each LOD)
- run the train.py with python and check the results directory for samples that will be generated from time to time
- In case the training crashes, you can resume the training by changing the params in training_loop.py, it will restart the training and create a new run
resume_run_id = 24,
resume_snapshot = None,
resume_kimg = 11160.0,

{kind=link}
{kind=link}
{kind=link}
{kind=link}
http://www.aiobjectives.com/2019/10/31/what-is-simple-linear-model/
A neural network is a network or circuit of neurons,
or in a modern sense, an artificial neural networ
composed of artificial neurons or nodes.
… The connections of the biological neuron
are modeled as weights. A positive weight
reflects an excitatory connection, while
negative values mean inhibitory connections.
http://www.aiobjectives.com/2019/10/31/on-chip-off-chip-memory-storage-in-artificial-intelligence/
chip memory it means when the processor needs some data, instead of fetching it from main memory it
fetches it from some component that is installed on processor itself. The data that a processor
frequently needs is prefetched from memory to SRAM to decrease the delay or the latency. SRAM is
used as on chip storage; its latency rate is less usually single cycle access time and it is
considered as a cache for DRAM.
Thanks for a great blog. I was wondering how did you get all the images from chrono24 . Can you please include the method/code in the blog .
No sorry, I can’t
Dear Christian Freischlag,
I hope this email finds you well, I followed your watch production project. very interesting results.
I was wondering if you could show me how to mix source A, source B watch to get a new watch?
like the character fusion but for watches instead of faces
thank you in advance for considering my request and looking forward hearing from you soon
Best Regards
Ahmed Ali
PhD candidate
Building Construction Engineering and Management Lab
Department of Architectural
CHUNG ANG UNIVERSITYOffice
Hi Ahmed,
thanks for your question. A problem with StyleGAN is that you can not apply it on any images to mix their “appearance” as long as they are not encoded inside of the GAN itself. To mix two images of watches you have to first find the internal representation of both watches in the latent space (which can be different from your real images). Once you have those latent vectors, you can mix them up, as you wish. Finding these latent vectors is not easy, but some work exists (StyleGANLatentEncoder). In StyleGAN2, the projector is included. Hope that helps, Cheers Christian
wow,
thank you very much, I really appreciate your valuable comment, I have already trained my watches for a week now I can produce new watch using tutorial posted by Mathias Pfeil (https://www.youtube.com/watch?v=QBUFrep8ljI). Now, I have .pkl file of my trained model.
next step is to find the latent space of my (source A, and source B) watches. the problem is all the tutorial that show you latent spaces are for human faces that they use pretrained VGG model + ffhq wich are H5PY format. I was wondering if you could guide me on how to find watch latent space of my source A image using using my .pkl file?
thank you in advance for considering my request
Best Regards
Ahmed Khairadeen Ali
PhD candidate
Building Construction Engineering and Management Lab
Department of Architectural
CHUNG ANG UNIVERSITYOffice
Hi again, I have not yet tried it but it sounds like your serialization format is just different. You can try to save your model as a h5py format too.
thanks again Christian for the quick reply, I was wondering if you could put the custom stylemixing code in a github repository so we researcher can learn from and use it in our research. I also wonder if you are interested in a collaboration research about stylemixing of custom dataset. I have the dataset, powerful computer, training setup, I will only need you to teach me how to get latent space of Source A and Source B, then mixing using AdalN. I am writing a journal article but stuck at this point. I would appreciate if you had time to be interested in my research. I am a PhD student in Architecture and interested in generating building facades by mixing two existing facades (Source A, and Source B).
Best Regards
Ahmed Khairadeen Ali
PhD candidate
Building Construction Engineering and Management Lab
Department of Architectural
CHUNG ANG UNIVERSITYOffice
Hi Ahmed, I didn’t use much custom code, I just used the StyleGAN style mixing code. Cheers
thank you very much for this explanation, I believe since you are expert in this field, you find style mixing is an easy task to accomplish. unfortunately, it’s been a quite long time I am stuck in finding the latent space vector of my watches. you recommended me to check styleganlatentencoder and I am still unfortunate to make it work for watches.
is there a possibility you could do a tutorial on “custom dataset stylegan latent vector encoding”. that would be very helpful for a lot of people who are insterested in GAN like me.
thanks again for all the effort you put in this article
Hi again, I wanted to look into it, unfortunately I didn’t find the time for it. If I find the time, I will share my insights and write a small tutorial, but I can’t promise anything 🙂
Dear Christian,
I have a quick question
how can I create stylegan model with (1, 18, 512)
my stylegan model is generating shape with (1, 12, 512) and when I try to use latent space encoder of my images I cannot find the latent space developed by Puzer because of shape difference
in more details:
my model produce shape with (1, 12, 512) using (https://github.com/NVlabs/stylegan) github repository
but when I use stylegan encoder (https://github.com/Puzer/stylegan-encoder) to find latent space, it requires (1, 18, 512), do you have any idea how can I produce (1, 18, 512) model shapes instead of (1, 12, 512)?
thank you in advance
Hi Ahmed,
I think you should have a (1, 18 512) vector produced by the styleGAn implementation, at least I have. You can see it in this line. If your vector is 12, you have probably the wrong tensor. Please also note that I am happy for feedback and substantive discussion regarding my articles, but I am not the free support for styleGAN implementation details, stackoverflow is the place for such questions. Cheers