If you ever trained a CNN with keras on your GPU with a lot of images, you might have noticed that the performance is not as good as in tensorflow on comparable tasks. In this post I will show an example, where tensorflow is 10x times faster than keras. I will show that it is not a problem of keras itself, but a problem of how the preprocessing works and a bug in older versions of keras-preprocessing. Finally, I will show how to build a TFRecord data set and use it in keras to achieve comparable results.
Measure if your GPU is used
When training a neural net on the GPU the first thing to look at is the GPU Utilization. The GPU-utilization shows how much your GPU is used and can be observed by either nvidia-smi in the command line or with GPU-Z. The GPU utilization translates direct to training time, more GPU utilization means more parallel execution, means more speed. If you are working on windows, don’t look trust the performance charts in the windows built-in task manager, they are not very accurate.
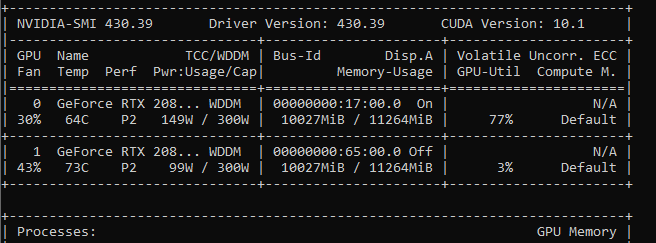
Training with keras’ ImageDataGenerator
First let’s take a look at the code, where we use a dataframe to feed the network with data. In keras this is achieved by utilizing the ImageDataGenerator class. In this example we use the Keras efficientNet on imagenet with custom labels. Additional information in the comments.
train_datagen = ImageDataGenerator(
rescale=1./255, # we scale the colors down to 8 bit per channel
rotation_range=30, # The image data generator offers a lot of convinience features the augment the data
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,
validation_split=0.1 # here we can split the data into test and validation and use it later on
)
# now we create a training and a test generator from a pandas dataframe, where x_col is the absolute path to the image file and y_col is the column with the label, disabling validate_filenames and drop duplicates speeds up everything for large data sets.
train_generator=train_datagen.flow_from_dataframe(dataframe=df,
directory=None,
x_col="ImagePath",
y_col="Label",
class_mode="categorical",
target_size=input_shape,
batch_size=batch_size,
subset='training',
drop_duplicates=False,
validate_filenames=False
)
validation_generator=train_datagen.flow_from_dataframe(dataframe=df,
directory=None,
x_col="ImagePath",
y_col=" Label ",
class_mode="categorical",
target_size=input_shape,
batch_size=batch_size,
subset='validation',
drop_duplicates=False,
validate_filenames=False)
# now we create the model loading the 300x300 efficientnet with imagenet weights, include_top= false drops the last fc layer, due we want to use our own.
base_model = EfficientNetB3(include_top=False, weights='imagenet')
# our custom fc_layer(top) with the number of classes we want
x = GlobalAveragePooling2D()(model )
x = Dense(len(train_generator.class_indices), activation='softmax', name='predictions')(x)
#create the model
model = Model(inputs=base_model.input, outputs=predictions)
# and now fit the model with 16 worker threads reading the images
history = model.fit_generator(generator=train_generator,
steps_per_epoch=train_generator.samples // batch_size,
validation_data=validation_generator,
validation_steps=validation_generator.samples // batch_size,
epochs=20,
workers=16,
verbose=1)
This works fine, it does what it should, but if we compare it to tensorflow implementations we notice that it’s much slower than in keras, even if we use 16 workers to make the preprocessing. But why is it still so much slower?
Data bottleneck
If we look at the GPU utilization with GPU-Z, we can observe a pattern:
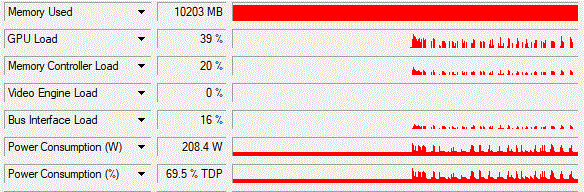
As shown in the image, the GPU is not used all the time the load is varying a lot. Additionally, the Memory Controller is also idling. It seems like the GPU is waiting for something. There are several possible reasons.
- Hardware: One reason could be loading data from HDD instead of SSD, which is not the case here. But if you use HDDs, you should really upgrade to an internal SSDs (not USB, either SATA or M.2).
- Other software: Another reason is often a virus scanner, which slows down the IO, if you have performance issues, whitelist your data folder.
- Configuration: It might be possible to speed up the training by using python mutliprocessing, but it seems like the windows version of keras does not support it. Also increasing the queue size and number of workers in fit_generator can help.
- Outdated version: I also noticed a difference between two computers, where one can utilize the GPU much better than the other, even with equivalent Hardware. It was simply because Keras-Preprocessing suffered from a Bug in version 1.0.9, which was fixed in 1.1.0! The GPU utilization increased from ~10% to ~60%
If nothing from the above helps we can take a look at the code and see that keras does the preprocessing on the CPU with PIL, where tensorflow often uses GPU directly. Furthermore, tensorflow offers TFRecords, which is a binary format, where images are stored raw bitmaps, which means the CPU doesn’t need to decode the jpeg files, every time it reads them. Furthermore, TFRecords ensures that the data is not fragmented in small files, which boosts IO performance.
Comparing the keras implementation with the tensorflow’s efficientnet implementation + TFRecords gives us much better results:
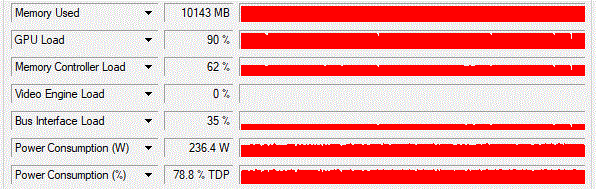
But we don’t get it for free. We have to convert our hole data set from jpeg images to TFRecords (Here is a short example) and we are now dealing with tensorflow not keras and tensorflow is pretty unhandy and we lose the benefits of the keras ImageDataGenerator.
Use a TFRecord dataset in keras
Well we won’t get back the ImageDataGenerator, but we can still work with keras and the TFRecod dataset. The TFRecord dataset api is ment for optimized IO performance and here we can read the images without jpeg decoding. Thanks to the keras developers they already support passing tensorflow tensors to keras, so we can use TFRecord datasets. In Tensorflow 2.0 it should be possible to directly train a keras model on the dataset API.
# This is the funciton used to decode the TFRecords
def _parse_function(proto):
keys_to_features = {"label": tf.FixedLenFeature([], tf.int64),
'image_raw': tf.FixedLenFeature([], tf.string)}
parsed_features = tf.parse_single_example(proto, keys_to_features)
image = tf.decode_raw(
parsed_features['image_raw'], tf.uint8)
image = tf.reshape(image, (300, 300, 3))
return image, parsed_features["label"]
def create_dataset(files, batch_size):
dataset = tf.data.TFRecordDataset(files)
dataset = dataset.map(_parse_function, num_parallel_calls=4)
dataset = dataset.repeat()
dataset = dataset.batch(batch_size)
iterator = dataset.make_one_shot_iterator()
image, label = iterator.get_next()
image = tf.reshape(image, [batch_size, 300, 300, 3])
label = tf.one_hot(label, num_classes)
return image, label
image_tensor, label_tensor = create_dataset(records, BATCH_SIZE)
base_model = EfficientNetB5(include_top=False, input_tensor=image_tensor, weights='imagenet')
x = base_model.output
x = GlobalAveragePooling2D()(x)
predictions = Dense(num_classes, activation='softmax')(x)
model = Model(inputs=base_model.input, outputs=predictions)
model.compile(optimizer=optimizers.Adam(lr=0.01), loss='categorical_crossentropy', metrics=['accuracy'],
target_tensors=[label_tensor])
model.fit(epochs=10,
steps_per_epoch=num_batches,
verbose=1
)
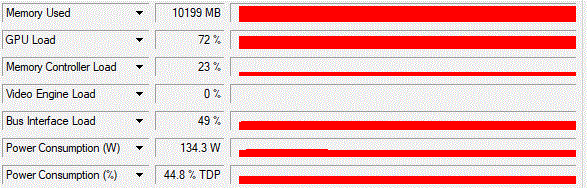
Now we have a GPU utilization of ~80 % in average, which is still a bit less than the 90% of the tensorflow implementation but much better than the varying (10% average) utilization of the pure keras implementation. I don’t have to mention that this increase from 10% to 75 % speeds up the training by factor 7.5.
Conclusion
If you have performance issues, first update all packages, especially keras-preprocessing. Deactivate your virus scanner and check if you have an internal SSD. Try to tweak the configuration on fit_generator (workers and queue_size). If you are using linux try out multiprocessing and a thread-safe generator. If nothing helps convert your dataset to TFrecords and use it with keras or directly move to tensorflow. If you already use tensorflow 2.0, you can directly fit keras models on TFRecord datasets.
If you have any ideas how to make it possible to use the ImageDataGenerator in this scenario or any other idea, please comment!
[…] Here is a more detailed explaination. […]
And how about data augmentation and all fancy ImageDataGenerator functionalities? How to substitute it using TFRecords?
Unfortunately you loose all the functionalities and you have to use the tensor operations available by tensorflow directly. I think you can cover the most functions with that, but it’s definitely more work. See here