Data leakage in practice is a widely underestimated effect in machine learning, which happens especially where a lot of feature engineering is involved. Data leakage happened even in Kaggle competitions, where winners exploited these systematic flaws in the data. This post is about why it is so hard to spot data leakage and why it is important to understand the features in depth from different perspectives to overcome data leakage.
Data Leakage, what?
The term data leakage isn’t as prominent in machine learning as it should be. A lot of people know the roughly the concept but don’t know the term and sometimes data leakage is also called target leakage, where the label is simply leaked into the training data. However, data leakage does not just mean that there is a 1-to-1 “leak” between the training and test dataset. It’s often more complicated, especially in machine learning models, where temporal data is involved. Data leakage in general is about correlation vs. causality.
The simple ones
The straight-forward example for data leakage is a dataset, where the training data simply contains a feature, which is highly correlated to the label, but has no causal realtion. For example, your label is the annual salary of employees and you have a feature which contains the monthly salary, in this case the annual salary is simply a function of your monthly salary. Another example is that each row is assigned to a group (e.g. user), which leaks the label from the test set, where the same group (e.g. user) exists. However, these examples are usually easy to spot with label importance and correlation analysis.
Duplicates
Harder to spot are duplicate samples in the data set. Consider a data set, where 20% are duplicates. When you divide your data into train and test, you already have a 20% accuracy advantage, just because of duplications. Your classifier can simply remember these examples.
Spotting duplicates in your data isn’t always that simple as you might think. In practice, they might be not 100% matches. e.g. You have a duplicate click event, which includes a timestamp with slightly different times. However, duplicates are often a bug in the data aquisition pipline and can be eliminated there.
Temporal dependence
The most dangerous data leakage problem occurs if your data contains temporal dependent data. IMHO this is the most underestimated data leakage problem and the reason why a lot of machine learning projects fail in practice, while they looked good before.
Data leakage in practice – an example
You created a snapshot from an SQL table, where your mighty SQL statement collected all features and the labels from your website to predict credit labels. Your data contains aggregations of time dependent events, let’s say one included feature is how many payment reminders are sent to the customer.
You train your ml model and engineer features; the scores look great and you report the success to your boss. The model goes live and because you work in a data driven company, where you actually measure how things perform, you get an email which states that after some tests you are informed that you model did not improve credit scoring at all. What happened?
Dynamic data
You just missed a very important fact about your data. The snapshot is fine at the point you fetched the data from the database, but it does not represent the data at the point, where the predictions are made. Your inference data does not match the training data.
In this example the number of payment reminders is just around zero at the prediction time and increases over time. The label changes when the user doesn’t pay, but the game is already lost, the decisions about risk is made before that label changes. You just build a ml model, which predicts what is already decided, a self-fulfilling prophecy.
The problem here is that you cannot spot the problem by looking at the dataset itself. In non-toy datasets, you don’t have perfect clean data, where you can find such problems, by correlations. You must know exactly where and WHEN the features of your dataset are created. To avoid such flaws for aggregated temporal data, you can make use of the same techniques as in time series forecasting, using a rolling window approach. Don’t ever include any data, which is not available at prediction time.
This by-the-way is the reason why a data scientist should be aware of how the pipeline is built and where the data comes from in detail. A CSV file can never be the starting point for any ML project, which purpose is predictive analytics.
Timeseries forecasting
In timeseries forecasting there are also a lot of examples around, where the authors just applied a train test split or cross-validation and predicted the stock market with high accuracy (at least in their leaky setup), claiming they a built cash machine.
The problem is that people tend to split dataset the same way as with non-timeseries datasets. Obviously, this is something you should avoid, as you effectively predict the past by the future and the future by the future, which works pretty good. In timeseries forecasting it’s important to use a sliding window, approach as mentioned here. Bu there are even more things to consider.
Usefulness of predictions when predicting events
In my post about click-based intent prediction I showed how to predict customer behavior based on click events and also mentioned that data leakage can be a huge problem, if not taken into account. If we want to dig a big deeper on what can happen here is a visualization of an example data point, using sliding windows.
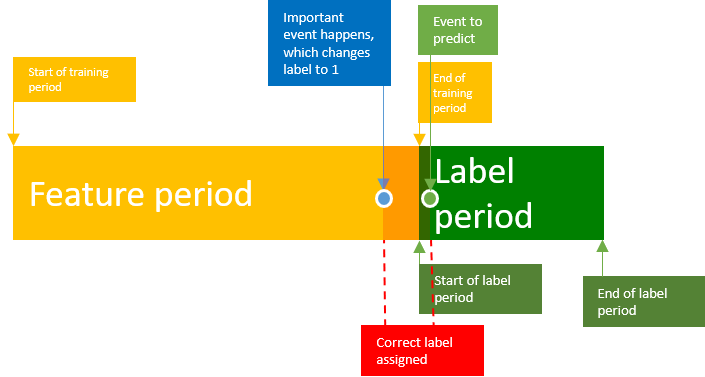
You can see a time period for gathering the events used as features and a time period for looking at our event to predict, strictly separated.
It might happen, that there is a significant event, which occurs just before the label period starts. In this case we only have a very limited time window, where the label is correctly assigned, but our prediction would be considered as correct for this sample. To overcome this problem, it’s important to slide the window though a long range for every single timestep and train the classifier for all of the samples.
Read more about data leakage in practice:
https://www.kaggle.com/dansbecker/data-leakage
https://conlanscientific.com/posts/category/blog/post/avoiding-data-leakage-machine-learning/