Understanding customer intent by clicks can improve customer journeys and enhance the overall user experience in eCommerce. An understanding of individual customers allows to customize the online experience in several ways. For example, it is possible to show them additional information, based on their behavior or recommend better products. Customer journeys in eCommerce can be represented by events (clicks) on the service provider site. This post shows how to use these clicks to predict user intent, using artificial neural networks .
Disclaimer
First let me say that I personally don’t like extensive tracking of activities by google or other large cross site advertising companies. That said, I think that individual websites can use similar techniques without being harmful to privacy, if their data is not shared or connected to any external service. It’s a difference, if I use data from users to make their experience a better one, or if I track activities across the whole internet to show advertisements. Furthermore, this personalization should be an opt-out.
Data representation of the sequence
Let’s start to look at the typical user data:
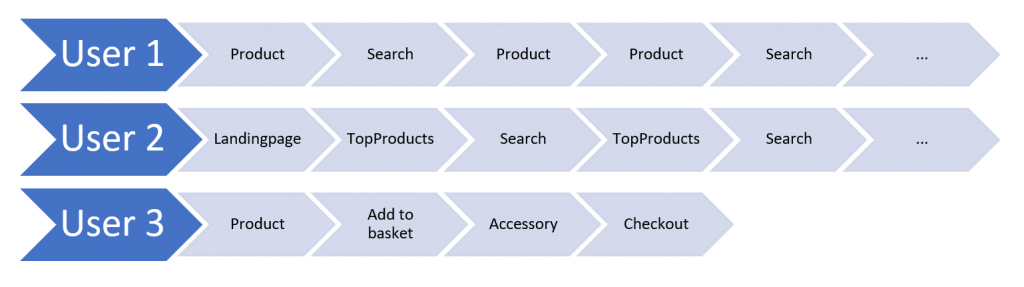
This image represents three different parts of user journeys, while interacting with a shop system. Obviously, every user has a different intent, but we can detect some patterns in their behavior. User 1 might be looking for a specific Product, while User 2 might be just browsing through the page. We can represent this journey as a sequence of events and each event can be represented as embedding inside the neural network. Using an embeddings space also make events comparable, like in NLP embeddings and furthermore we can deal with a large amount of events (e.g. if we use one event for each article in the shop). This number of distinct events is the counterpart to the vocabulary size in NLP.
Another important parameter is the maximum sequence length. The number of events in click streams can be very different for each user and session. At some point we must make a cut. The exact numer depends on the data, but the 90th percentile should be a good starting point.
Target variable
As we don’t know what the real intent of a user is, we need some proxy. We could cluster (sequence clustering) all the different sequences into such intents, or we could use a target event as a proxy e.g. a successful order.
In case of predicting intent, it’s important to divide the data into time windows. One window (X) represents the click data before time t0 and the second window represents data after t0, this is where we expect the target event Y to happen. In comparison to the image below, click data is not a continuous value, but the idea of the window approach gets clear. We could for example use a window of 6 hours to predict if the customer purchases something in the next 6 hours. Or we could even use real time data and continuously predict the next action.

“Time-series Extreme Event Forecasting with Neural Networks at Uber”.
After having a target event, we can construct a problem to solve within a classifier. Considering we have a list of events, which are already encoded as integers, we can transform the data like this:
from keras.preprocessing.sequence import pad_sequences
import numpy as np
num_events = 8 # example
seq_len = 10 # example
events = [
[1, 2, 1, 2, 1], # 'user1'
[3, 4, 2, 4, 1], # 'user2'
[1, 5, 6, 7]] # 'user3' purchase
x = pad_sequences(events, seq_len)
y = [0, 0, 1]
(x, y)
Output:
(array([[0, 0, 0, 0, 0, 1, 2, 1, 2, 1],
[0, 0, 0, 0, 0, 3, 4, 2, 4, 1],
[0, 0, 0, 0, 0, 0, 1, 5, 6, 7]]), [0, 0, 1])
With a simple LSTM model we could then classify the sequences. In this example we generate 1000 random example sequences, which will obviously converge to 50% accuracy.
from keras.layers import Embedding, LSTM, Masking, Input, Dense
from keras import Model
import random
y = np.random.choice(2, 1000, replace=True)
x = np.random.randint(num_events, size=(1000, seq_len))
net_in = Input(shape=(seq_len,))
emb = Embedding(num_events, 8, input_length=seq_len, mask_zero=True, input_shape=(num_events,))(net_in)
mask = Masking(mask_value=0)(emb)
lstm = LSTM(64)(mask)
dense = Dense(1, activation='sigmoid')(lstm)
model = Model(net_in, dense)
model.compile('adam', 'binary_crossentropy', metrics=['acc'])
model.summary()
history = model.fit(x, y, epochs = 5, validation_split=0.2)
Using convolutional layers
In the recent years convolutional layers have shown very good performance on sequence classification tasks as well. The idea is just to go through the sequence with a 1D convolution. For convolutional networks we have several “parallel” convolutional connections. In keras we can apply such a convolutional sequence classification with this model:
net_input = Input(shape=(seq_len,), name='net_input')
emb = Embedding(input_dim=num_features, output_dim=16, input_length=seq_len, input_shape=(seq_len,),
mask_zero=False)(net_input)
c1 = Conv1D(256, 3, padding='valid', activation='relu', strides=1)(emb)
p1 = GlobalMaxPooling1D()(c1)
c2 = Conv1D(128, 7, padding='valid', activation='relu', strides=1)(emb)
p2 = GlobalMaxPooling1D()(c2)
c3 = Conv1D(64, 11, padding='valid', activation='relu', strides=1)(emb)
p3 = GlobalMaxPooling1D()(c3)
c4 = Conv1D(64, 15, padding='valid', activation='relu', strides=1)(emb)
p4 = GlobalAveragePooling1D()(c4)
c5 = Conv1D(64, 19, padding='valid', activation='relu', strides=1)(emb)
p5 = GlobalAveragePooling1D()(c5)
x = concatenate([p1, p2, p3, p4, p5])
x = BatchNormalization()(x)
x = Dense(128, activation='relu')(x)
out = Dense(1, activation='sigmoid')(x)
model = Model(net_input, out)
Conclusion
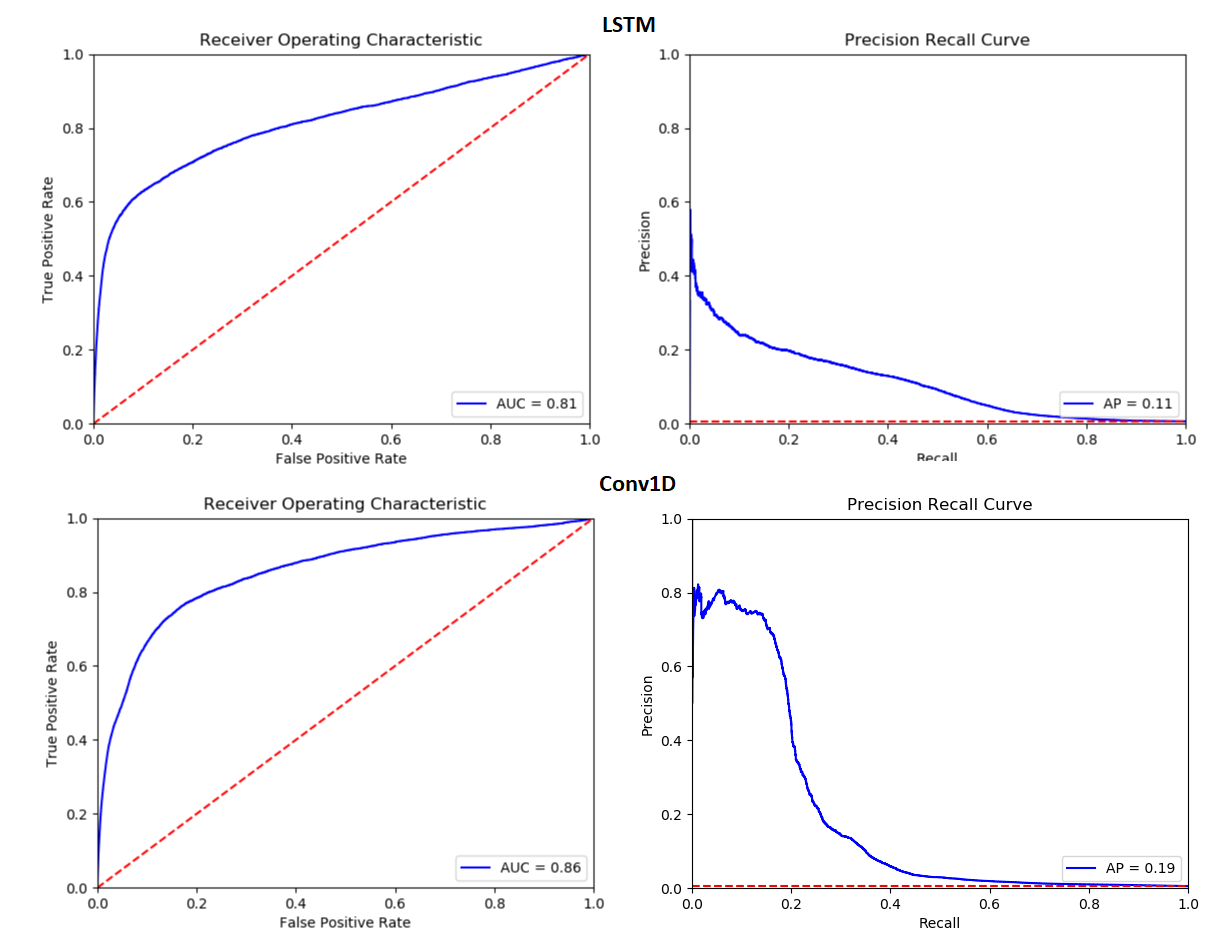
It turns out, that the CNN approach outperforms LSTMS in many ways. Convolutions are cheaper, so computation is fast, LSTMs are more sensitive to hyperparameters so with convolutions the model gets more robust and furthermore even the accuracy increases slightly. At least I noticed a better performance with convNets. As I did not use a public data set, I can only share the raw metrics:
Be aware of data leakage
The most important thing is to make sure, that your events are not self-fulfilling prophecies. If an event is included, which leaks the label, your model is not very useful (e.g. including the pay button click for purchase prediction). There is no general rule which events to exclude, but if your classifier performs extremely well on such a task, you might have a leaky feature. Intent prediction will never give you high accurate models, because the event data is usually not very clean and specific enough.
Hints
In reality, data is not perfect, we often have duplicate events, bots or other noise. Before starting to classify sequences, make sure your data is corrected. Filter out unusual behavior, like bots and crawlers. Merge duplicate events and split sessions from users by a meaningful inactivity time. You can also bring in time into the model (e.g. put time_since_last_event on top of the embedding vector). It may be feasible to not only use a max seq length, but also a min seq length. And if the target event is very rare, undersampling is a option.
Another idea to improve the model, would be attention. Attention is pretty hot in NLP, where the text is also a sequence of word or characters. Could be applied here, too.
More details and references
Conversion prediction with click streams


[…] You can find the article here. […]
[…] my post about click-based intent prediction I showed how to predict customer behavior based on click events and also mentioned that data […]
[…] my post about click-based intent prediction I showed how to predict customer behavior based on click events and also mentioned that data […]
[…] my post about click-based intent prediction I confirmed the way to predict buyer habits based mostly on click on occasions and in addition […]
[…] my post about click-based intent prediction I showed how to predict customer behavior based on click events and also mentioned that data […]
Hello Christian,
Good work! IMO, one of the key tasks is relating to how one enumerates the clickstream data. Do you have some examples that you can share? Thank you.
Hi David, thank you. Not really sure, if I got it right. But when I think about the project I was referring to, I applied padding and cutoff. I took only the last n events in the given time window. I also did not encode the “time past since last event” into the final model (I tried and it did not improve), so that only the sequence without information about time between events was included. I hope this answer helps. Cheers Christian
Hi Christian, please let me rephrase my question. A sequence is a collection of events. My question is regarding these events: can you give a description or definition of these events? Thank you.
Hi David, ok I see. It depends on what to predict and what data is available, but in my case it was basically the interactions with the website. e.G. Used Search, Visited Product, Showed Image, read FAQ etc. Cheers Christian
Can you please list the 8 events used in the model? I am a bit surprised that you have only 8 events. It would be great to know what they are. Thank you.
Sorry the 8 events are just for demonstration in the post, in reality it was more like hundreds of different events.
You can think of every interaction with the website.
Can you at least give a couple examples?
Typical customer journey events like: login, search, type of product shown, category shown, FAQ read etc.
Thanks. Now I know we use similar methods. I have about 1200 events, and millions of rows of data. How do you handle the issues associated with large amount of data? I think our method is similar to Bag-of-Words embedding. Have you tried Word2Vec method? Thanks.
Hi David, I would say it’s more like Word2Vec than BoW, as the indices of the events directly go into the embedding layer. I had also millions of rows and the bottleneck was actually not the GPU, but the data pipeline (padding the sequences). I ended up with several hundreds of gigabytes of TFRecord data to speed up training.