In 2017 and 2018 GANs have significantly contributed to the visibility of artificial intelligence. Impressive images generated by GANs have been published and one was even sold for 432 500 $ in an Christies auction. The good thing with GANs compared to other deep learning architectures, is that they are pretty easy to apply on new image datasets, because GANs are semi-supervised.
In this post I want to show, how I used ProgressiveGANs for generating artistic watch images.
How do GANs work?
GANs consist of two major parts, the generator and the discriminator. The generator takes random noise as input and generates an image out of it. The discriminator tries to detect whether the generated image is a real image or a fake image. With this simple game, the generator is learning by failure. If a generated image is detected as fake, the generator updates its computation (weights). If the discriminator predicts the fake image as real, it is also updated. Real and fake images shown to the discriminator is alternating.

Progressive GANs
Training GANs is very time intense and error-prone. Basically, the generator learns how mimic the samples from scratch and this is a very heavy task, prone to vanishing gradients and mode collapse. To reduce the training time, ProgressiveGANs have been introduced in 2017. Progressive GANs do not start with the full-size image, instead they increase the image size step by step. This reduces the complexity and additionally improves the quality of the results. Furthermore, they are using Wasserstein distance as a loss metric.
Read more about WGANs and PGANs!
Data
The dataset consists of more than one million images from chrono24. The images show luxury watches from all kinds, while some very popular watches like the Rolex Submariner, Daytona, Omega Speedmaster, Audemars Piguet Royal Oak are very frequent. The majority of the images show watches from the front and are resized to 256×256.
Training
I used the implementation from here with some minor changes. I used only 256×256 images to start with and started with a Geforce GTX 970, which was way to slow. Later I upgraded to the RTX 2080 TI, which is a huge performance boost and furthermore has enough memory to increase the batch size. The training took approximately two weeks and several restarts until the GAN worked as intended.
In the first stage of the training, the network uses just an 4×4 image and learns how to mimic a watch in this size. The resolution does not allow any visible watch but with the next stage (8×8) its getting more interesting. With 16×16 pixels you can already recognize a watch.
For the network it is much easier to learn this way, because every time the image size is increased, it can just split every pixel into four sub-pixels. All of them have the same starting point, but will be fine-tuned in the next stage. This can be repeated until the GAN has grown to the final size. Here are some examples of the training.
-
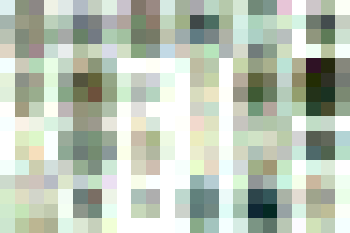
4×4 -

8×8 -

16×16 -

32×32 -

64×64 -

128×128 -

256×256
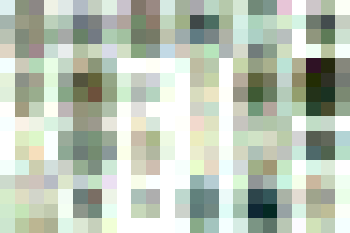






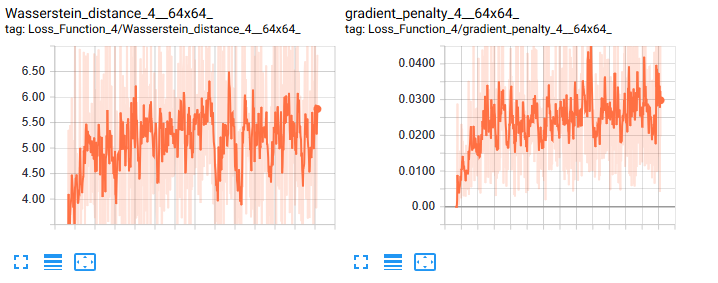
At the beginning of the training the generated images are not detailed enough to allow conclusions about the model. Furthermore, looking at the loss curve in tensorboard seems like the model does not learn at all or something is wrong with it. But don´t get fooled by GANs loss metric. When the discriminator and the generator are learning, they are both competing, which means if the loss for the generator decreases (better generated images), the loss of the discriminator is increasing (harder to detect fakes).
Fake watches
While the GAN produces some almost realistic watch images, most of the images are close to original watches, especially close to the very popular watches. Sometimes the GAN mixes up bracelets, colors and materials. Note the watermark, which was visible on the input images.



















Artistic watches
Artistic images are quite impressive, much more than the good fakes. Enjoy!
















































Watch out for more GAN content in the near future!


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
[…] WatchGAN: Using generative adversarial networks for artificial generated watch art […]