In my previous post i showed how to increase the parallelism of spark processing by increasing the number of executors on the cluster. In this post i will try to show how to distribute the data in a way, that the cluster is able to process the data efficiently. The key to get to this state, is data partitioning.
Heterogeneous partitions
In the most tutorials, the data is very well distributed. But in practice sometimes we need to operate on data, which is sorted or somehow pre-processed that partitions are very different in their size. Think about accesslogs, were we group the data by IP and we want to save them partitioned by these IPs. When using the straight forward solution and just save the data with the default dataframe API df.write.partitionBy(“ip”) you will notice that the job will take ages to complete, if you are dealing with big data.
Custom partitioning
Sometimes we can solve this problem inside the Dataframe API, just by using partitionBy(“IP”, 1000), which asks Spark to make 1000 partitions. But in the most cases this wont fix the problem. Sadly the Dataframe API does not offer us the possibility to use a custom partitioner and so we need to go down to Key-Value RDDs. On the RDD level we can exactly define, how we want to distribute our data into partitions. This is how we can define a partitioner:
class CustomPartitioner[V](
partitions: Int,
elements: Int)
extends Partitioner {
def getPartition(key: Any): Int = {
val k = key.asInstanceOf[Int]
// magic
return partition
}
}
Now we can think about how we can partition the data to make it easier for Spark to save the data by IP. To do so, we need to count the records by IP first, to get a understanding how the data looks like and use it for our partitioning algorithm. After that we need to use the keyBy() function to get a PairRDD. In this constructed example there is one huge IP with millions of records and other IPs with little records. A simple approach is to split the big IP into several partitions and merge the small IPs together, so that the partition sizes roughly match. Of course this is very simple and there are better approaches like partitioning algorithms.
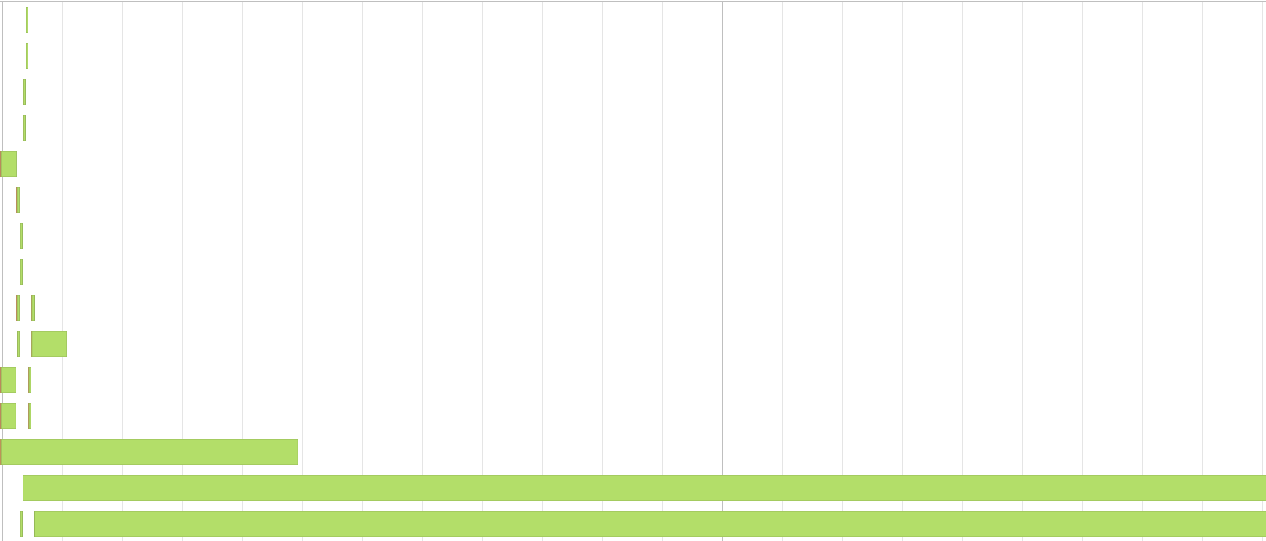
Here you can see what happens in the Apache Spark Event Timeline, when your partitions are very different. Some tasks succeed almost instant, while few take very long. You don´t profit from the parallelism.
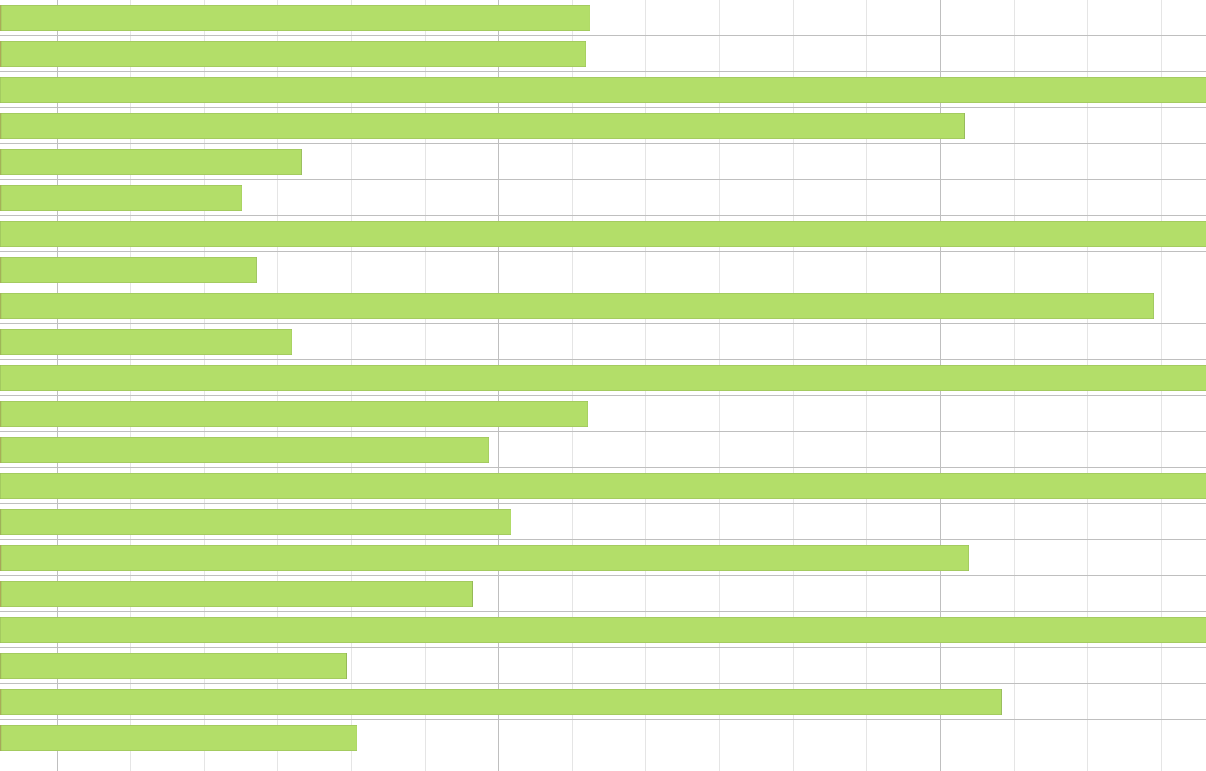
Here you can see how it looks like after the custom partitioning is done. Still not perfect, but much better.
Expanded Keys
Another approach to get better partitions it to manipulate the key in the PairRDD and use a default HashPartitioner. If we just append a random value to the Key (as concatenation) the data is more distributed across the partitions. In the IP example we could do something like this:
val r = scala.util.Random
val betterPartitions = rdd
.keyBy(_.getAs("IP").toString)
.map{case (key, value) => (key+r.nextInt(10), value)}
Conclusion
Repartitioning of data can speed up the processing in big data sets. But there is also some overhead, so its useful when the task processing time per record is long or the partitioning matches the output partitioning. It is possible to get speedups of 10 or more in some cases.
