This ist the third part of the Kaggle´s Machine Learning by Disaster challenge where i show, how you can use Apache Spark for model based prediction (supervised learning). This post is about support vector machines. The Support Vector Machine (SVM) is a non-probabilistic classifier, which tries to maximize the gap between two classes. We will first take a look at used features from the naive bayes classification and then show how to get them into a SVM.
Features
In last post we used naive bays classification. We filled in missing values and build a simple model, which reaches a hit ratio of ~0.6. For the classification we used: Fare, Pclass and the Age of the passengers to predict survival. If we just put the feature vectors into the SVM model, we get bad results and the reason why is that in comparison to Naive Bayes, the SVM does not scale features by design. We need to scale values before we can train the model to prevent that Fare is the dominating feature (values up to ~500), while Age goes only up to ~80. Pclass needs also some transformation, because it´s a categorical feature. And well we also missed features, which could make the model much better.
Feature Scaling
The simplest way to scale features is to scale them with x´ = x – min(x) / range(x).
def scaleValue(min: Double, range: Double, value: Double): Double = {
(value - min) / range
}
For support vector machines and machine learning its common to use another approach. x´ = x – mean(x) / stdev(x). Spark offers this standard method with the StandardScaler class. I have tested both and they don´t lead to different results in this case.
val scaler = new StandardScalerModel(stddev, mean) (...) val scaledContinous = scaler.transform(Vectors.dense(fare, age))
Categorical Features
To deal with these kind of features, we split every category into a single feature, using one-hot-encoding. So Pcalss (1.0 – 3.0) turns into p1, p2, p3. (1,0,0 | 0,1,0 | 0,0,1). We could also stay with the original values, but as they are not related to each other and are not continuous.
def flattenPclass(value: Double): (Double, Double, Double) = {
if (value == 0)
(1, 0, 0)
else if (value == 1)
(0, 1, 0)
else (0, 0, 1)
}
New Features
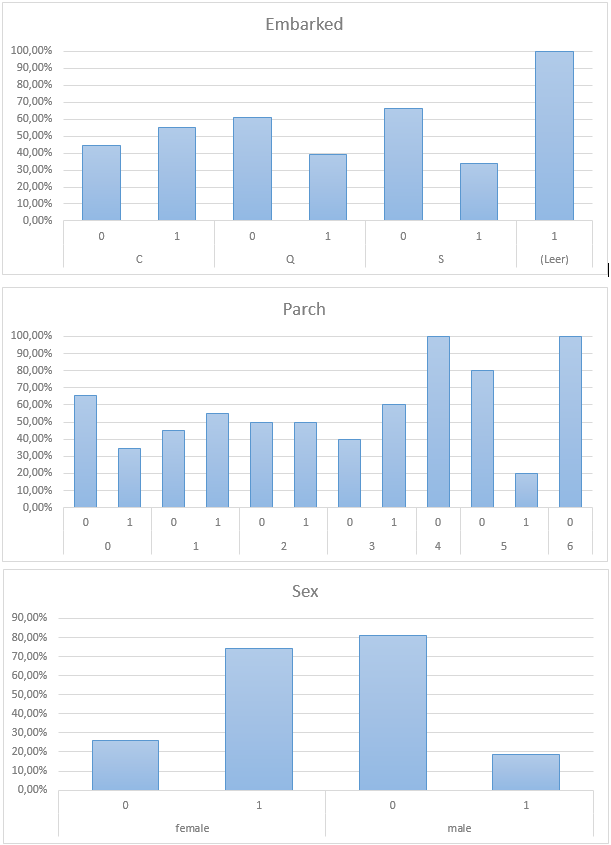
Now we have scaled the data and prepared it for the SVM, we can also use some more features. At this point we should step back and take a look at the data again. You can see some missing feature candidates on the excel pivot chart image.
The Sex attribute really matters here, we should definitely include in into the prediction. Embarked does also show some small differences, we will put it in. Parch does not look very imported here.
def getScaledVector(fare: Double, age: Double, pclass: Double, sex: Double, embarked: Double, summary: MultivariateStatisticalSummary): org.apache.spark.mllib.linalg.Vector = {
val pclassFlat: (Double, Double, Double) = flattenPclass(pclass)
val embarkedFlat: (Double, Double, Double) = flattenEmbarked(embarked)
Vectors.dense(
scaleValue(summary.min(0), summary.max(0), fare),
scaleValue(summary.min(1), summary.max(1), age),
scaleValue(summary.min(3), summary.max(3), sex),
pclassFlat._1,
pclassFlat._2,
pclassFlat._3,
embarkedFlat._1,
embarkedFlat._2,
embarkedFlat._3)
}
PCA Principal Component Analysis
Apache Spark does also offer some methods for dimensionality reduction. One of them is the PCA, which does try to mode the features into a new coordinate system with less dimensions. Using PCA in Spark is pretty simple, we take out feature vectors and put them into the the PCA.
val pca = new PCA(scaledData.first().features.size).fit(scaledData.map(_.features))
val pcaData =scaledData.map{
lpoint => LabeledPoint(lpoint.label, pca.transform(lpoint.features))
}
Don´t forget to apply these transformation to the validation dataset.
Support vector machine
So now we have the function to transform the features into scaled dense vectors. Lets apply this function to the input data and put them into the SVM.
val scaledData = trainingDf.map { row =>
LabeledPoint(row.getAs[Int]("Survived"),
getScaledVector(row.getAs[Double]("Fare"), row.getAs[Double]("Age"), row.getAs[Int]("Pclass"), row.getAs[Int]("Sex"), row.getAs[Int]("Embarked"), scaler))
}
//scaledData.saveAsTextFile("results/vectors")
val model: SVMModel = SVMWithSGD.train(scaledData, 100)


Part 1: Exploration
Part 2: Naive Bayes
Part 3: SVM
Part 4: Random Forest
Part 5: ANNs