In the previous post i showed how to use the Support Vector Machine in Spark and apply the PCA to the features. In this post i wills show how to use Decisions Trees on the titanic data and why its better to avoid the PCA in the Random Forest algorithm.
A hint from the last scores: Its kind of shattering, that the SVM and all previous models did not better perform than just deciding by gender. On the kaggle leaderboard there are some markers, the simple gender based prediction also scores 0.76555.
Random Forest
The Random Forest is a advanced decision tree algorithm. Decision trees are very simple to understand. They build a graph of the training data by observing probabilities and end up a class (see the image from Wikipedia).
Random forest goes one step further, it uses multiple trees (a forest) by splitting the training data into random parts and then build up the decision tree for each partition. The major beliefs are that every tree does a correct decision for the most of the data. And if a tree does a wrong prediction, others won´t. So every tree can vote for a class and the class with the most votes wins.
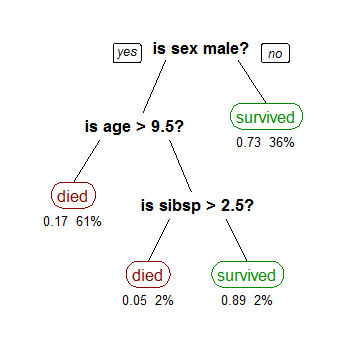
Spark Random Forest
In Spark the random forest classifier can be parameterized with these options:
- numTrees – how many trees should be created
- featureSubsetStrategy – how much features used for spliting the nodes
- impurity – see here
- maxDepth – how deeo can a tree be
- maxBins – bins for continuous features
And the code:
val numClasses = 2
//val categoricalFeaturesInfo = Map[Int, Int]((2, 3), (3, 2), (4, 3))
val categoricalFeaturesInfo = Map[Int, Int]()
val numTrees = 96
val featureSubsetStrategy = "auto"
val impurity = "gini"
val maxDepth = 4
val maxBins = 100
val model = RandomForest.trainClassifier(scaledData, numClasses, categoricalFeaturesInfo,
numTrees, featureSubsetStrategy, impurity, maxDepth, maxBins)
Random forest with these parms gives us a score of 0.77990!
PCA
When applying a PCA before Random forest, the results get worse. When we think about it it makes sense, because PCA throws features away, which could be may used in the decision trees. Anyway the titanic data is not big data, far away from it. In a real example with much features it could be useful, because the trees would be much smaller.
I also noticed that gradient boosted trees didn´t perform very good, you can check it yourself on github.


Part 1: Exploration
Part 2: Naive Bayes
Part 3: SVM
Part 4: Random Forest
Part 5: ANNs