After getting good results with the Random Forest algorithm in the last post, we will take a look at feed forward networks, which are artificial neural networks. Artificial neural networks consist of many artificial neurons, which are based on the neurons of brains. Apache Spark offers the class MultilayerPerceptronClassifier, which is kind of new in Spark (since 1.5) and provides a configurable implementation of feed forward networks. This is the last post about supervised learning with the titanic data set, but i will continue with another data set and unsupervised learning algorithms.
Prepare the data
The MultilayerPerceptronClassifier is based on the Dataframe API, instead of the RDD[LabledPoint]. So the first thing to do is to convert the data into the Dataframe. Its not that straight forward, when using the existing code. First we don´t need LabledPoints, we just use a Dataframe with the Spark default column names for lables and features. The good thing is, we can preserve every other column and Spark only uses these two. The input Dataframe is mapped to a tuple of label and feature and the converted to the Dataframe.
import sqlContext.implicits._ //needed for toDF
val scaledData = trainingDf.map { row =>
(row.getAs[Int]("Survived").toDouble,
Util.getScaledVector(row.getAs[Double]("Fare"), row.getAs[Double]("Age"), row.getAs[Int]("Pclass"), row.getAs[Int]("Sex"), row.getAs[Int]("Embarked"), scaler))
}
val data: DataFrame = scaledData.toDF("label", "features")
Artificial neural network
The Spark implementation requires that every input variable has a single neuron defined, these nodes are called the input nodes (input layer). On the other side there is the output layer. The output layer uses a function called soft-max scaling as activation function. The hidden layer is placed between the output and the input layer and uses the logistic function as activation function. The layers are connected by connecting the inputs from the current layer with the output of the layer before with a weight. When the network is trained, the weights are updated by the wrong classified feature vectors until the best weights are found.
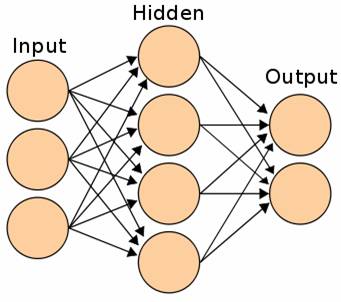
Now we have the data prepared, we can use Spark to train the model. First we need to define the number of nodes per layer. We have a feature vector of 10 variables, so we need to define 10 input nodes. The hidden layer is often sized between the input layer and the output layer (or sized via pruning) but i found 1 hidden node is working best. The output layer has 2 nodes, because we have two classes. The hidden layer can also consist of more layers then one.
Parameters
- the block size does optimize computation, by stacking vectors into matrices.
- seed is used for the initial weights
- Tol is the convergence tolerance (smaller -> slower)
- MaxIter tells Spark to stop after the number of iterations
val layers = Array[Int](10, 1, 2)
// create the trainer and set its parameters
val trainer = new MultilayerPerceptronClassifier()
.setLayers(layers)
.setBlockSize(128)
.setSeed(1234L)
.setTol(1E-6)
.setMaxIter(500)
val model = trainer.fit(data)
The perceptron
The perceptron for itself is in the simplest case a linear classifier, which is related to the support vector machine. Unlike the SVM , the perceptron does not find the best fitting of the separating line. When the perceptron is used in multilayer applications the activation function need to be non-linear, if we want non-linear classification.In Spark (and many other frameworks) the logistic function (sigmoid) is used.
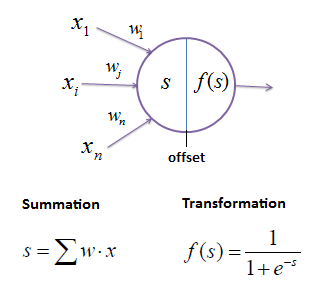
The perceptron as a linear classifier uses weighted inputs and an offset.
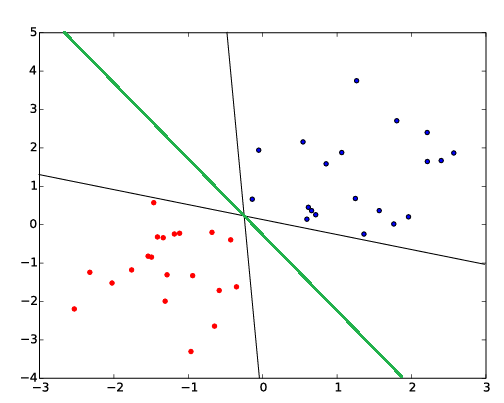
Both black linear boundaries are valid for the perceptron, because the costs only include if a point is wrong classified or not. The green line is the best linear boundary, calculated with the SVM (maximizes the gap).
Prediction
So after the model is trained we also need a validation Dataframe. To do so we create a Dataframe with PassengerId and a features column and put it into the model.
val vectors = validationDf
.map(row=>(row.getAs[Int]("PassengerId"), Util.getScaledVector(row.getAs[Double]("Fare"), row.getAs[Double]("Age"),
row.getAs[Int]("Pclass"), row.getAs[Int]("Sex"), row.getAs[Int]("Embarked"), scaler))}
.toDF("PassengerId", "features")
val predicted: DataFrame = model.transform(vectors)
Now we can save the Result and we are done!
Kaggle gives us a Score of 0.74163 for the feed forward network, which is pretty ok. Check out the code on github!
Recap
So after using bayes, SVM, decision trees and finally an artificial neural network it seems that the best result for the small titanic data set is the decision tree. Its not very surprising, as there is a dominant feature (gender) and a lot of categorical features. Anyway the titanic data set is nice, because is shows some basic problems of supervised learning and tells a story. For the exploration of unsupervised learning methods in Spark, i will try to find a better and bigger data set.


Part 1: Exploration
Part 2: Naive Bayes
Part 3: SVM
Part 4: Random Forest
Part 5: ANNs