In Apache Spark the key to get performance is parallelism. The first thing to get parallelism is to get the partition count to a good level, as the partition is the atom of each job. Reaching a good level of partitions is the data side of getting parallelism, but in this post we will take a look at the configuration and how to get as much executors we can.
Executors, Tasks and Memory
Executors are containers, which take a Task and compute them. (If you ever did something with OpenCL or CUDA you will find some similarities to the execution model). The image from the Spark documentation shows, how it works.
Often one executor is a node in the cluster, but if your nodes are powerful it would be a waste of resources to use only one executor per node. Here is the point where the config comes into play. What we want to achieve is that we have multiple executors per node so that we consume the complete memory. This sounds easy, but in practice it takes some time.
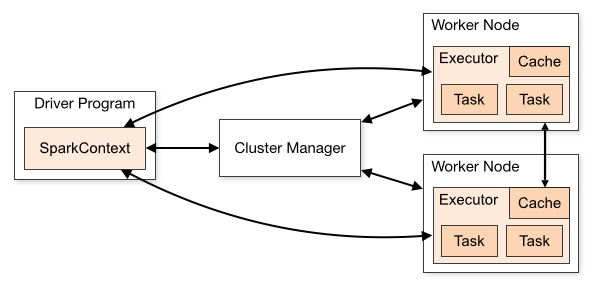
The spark execution model
Mulit-core and Caching
But wait, we missed something. When we think about an executor in the most cases there are many cores available. So an executor can also run multiple parallel tasks, when utilizing multi-core processors. But when using more cores, each task will consume memory, so why do we just reduce the cores to 1 and get the number of executors up? As you see on the image there is a cache in the executor, so if you want to use 1 single core, you will loose the effect of the cache, which can be a huge impact. On the other hand it is not recommended to use all available cores on a node to drive parallelism. It seems that the number of 5 is the maximum, which spark can handle in a good way.
Memory
Spark has more then one configuration to drive the memory consumption. The main option is the executor memory, which is the memory available for one executor (storage and execution). But there are also some things, which needs to be allocated in the off-heap, which can be set by the executor overhead. So the naive thought would be that the available memory for the task would be (executor memory / cores per executor), but its not that easy. Spark has does split the memory into execution and storage areas. The memory fraction (0.75 by default) defines that 75% of the memory can be used and 25% is for metadata, data structures and other stuff. The storage fraction (default 0.5) is used to split the 75% again into a cache and a area, which can be evicted. So the cache area is the place where RDDs are cached, if you persist them into memory and the rest is the execution cache.
That leads us to the available memory for each task: (executor memory * memory fraction / cores per executor) and for storage (executor memory * memory fraction * storage fraction/ cores per executor).
| config option | default | description / spark-submit option |
|---|---|---|
| spark.executor.instances | 2 | the number of executors / –num-executors |
| spark.executor.memory | 1g | the memory of the executors / –executor-memory |
| spark.yarn.executor.memoryOverhead | executorMemory * 0.10 | overhead memory of executors |
| spark.executor.cores | 1 | number of used cores per executor / –executor-cores |
| spark.memory.fraction | 0.75 | memory percent which can be used from spark application |
| spark.memory.storageFraction | 0.5 | memory percent which can be used for storage |
| spark.memory.offHeap.enabled | false | use of unaligned unsafe memory (link) |
| spark.memory.offHeap.size | 0 | size of offheap memory (not sure but it seems it takes the overhead memory from the executor) |
How much memory does my task need?
So with that info we can now calculate, how much parallelism we can get in theory. The major problem is now to get some idea, how much memory does my application/task need. The problem here is that heterogeneous partitions lead to different memory footprints. The best way to go for me, was to run the application with enough memory and profile the memory usage, take the maximum and add some safety to it. Well at the end you need to try ist out, but with that knowledge you can make better predictions and find the best setting faster.
Example:
The application uses 4 GB Ram + 2 GB offheap memory (profiling). The cluster has 25 nodes each with 12 cores and 64 GB RAM.
We want to use 4 cores per node, as we noticed that more then 4 does not benefit our application. So when running on executor per node we should get a parallelism of 25 * 4 = 100. The off-heap memory also increases, when we increase the number of cores, if you use tungsten off-heap memory. So we end up with (4GB+2GB)*4 = 24GB memory usage. Now we can double the parallelism when starting 2 executors per node (48GB/64GB) and we have halved the execution time (in theory). In practice its often not that good, because it depends on IO, network or just other jobs on the cluster, but it will be significantly faster in the most cases.
Links
- You should also think about dynamic allocation
- Great cloudera post
- Spark Tuning page
- Spark on Yarn
- Spark configuration

[…] my previous post i showed how to increase the parallelism of spark processing by increasing the number of […]