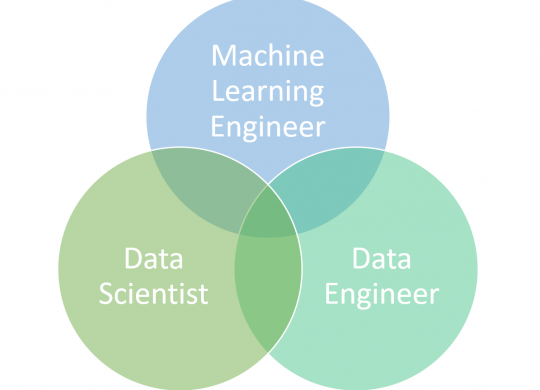
In the past years a new job role has become very popular (at least I noticed it in job postings and media). The machine learning engineer. But what is the difference between this new job role and data engineering or…
August 18, 2018 Read more